
Kiedy jakieś narzędzie cyfrowe staje się ważne w naszej organizacji lub pracy, zaczynamy poważnie myśleć o bezpieczeństwie danych, które do niego trafiają. Narzędzia generatywnej sztucznej inteligencji wyjątkowo szybko dotarły do tego momentu. Przyjrzyjmy się temu, jakie mamy alternatywy do rozwiązań komercyjnych i chmurowych. Czy, a jeśli tak, to jak możemy korzystać z AI na swoim komputerze?
Lokalny model AI
Kto zajmował się choć trochę cyfryzowaniem swojej organizacji, ten wie, że nie da się w pewnym momencie uniknąć rozmowy o tym:
- gdzie są nasze dane?
- kto ma do nich dostęp?
- jakie są wady, zalety i koszty rozwiązań chmurowych vs. własnych?
Ten sam dylemat mamy coraz częściej wobec korzystania z narzędzi AI takich jak ChatGPT, Google Gemini, Microsoft Copilot i wielu innych, które zagościły w organizacjach lub w indywidualnej pracy większości z nas. Wiele osób korzysta z komercyjnych i chmurowych narzędzi AI, zdominowanych przez kilka amerykańskich firm Big Tech. Oczywiście możemy płacić za wyższe wersje tych usług, co daje lepsze gwarancje bezpieczeństwa itp. Cena za wygodę i dostępność takich rozwiązań to brak pełnej kontroli (np. zmiana lub zamknięcie usługi) oraz często dodatkowe lub zmienne koszty subskrypcji.
Warto na początek rozróżnić narzędzia AI (np. ChatGPT, Perplexity) od modeli (np. GPT 5.2, Bielik-7B-v0.1). Narzędzia AI to strony i aplikacje, przez które korzystamy z modeli. Model AI to kod oraz zestaw wag, czyli zakodowanej w modelu wiedzy na temat tego, jak operować językiem, prowadzić tzw. rozumowanie, pisać i tworzyć odpowiedzi w różnych formatach. Kiedy korzystamy z Gemini lub ChatGPT zwykle zwracamy uwagę tylko na to, czy korzystamy z najnowszej wersji modelu. Nie mamy za wiele kontroli nad dodatkowymi parametrami, ukrytymi za interfejsem narzędzia.
Lokalne modele AI można pod tym względem porównać do systemu Linux, który dostępny jest za darmo, ale musimy go sami zainstalować na komputerze i skonfigurować. Podobnie jak różne odmiany Linuxa rozwijają globalne społeczności, tak modele AI, które możemy uruchomić lokalnie, tworzą i rozwijają firmy i organizacje z całego świata, a kolejne podmioty, modyfikują i ulepszają wersje poprzedników. Linux nie obiecuje, jednak tak reklamy systemów komercyjnych, że będzie działać idealnie bez odrobiny wysiłku z naszej strony. Podobnie lokalne modele AI. Mogą oferować nam bardzo zbliżone, a nawet takie same możliwości techniczne, co komercyjne narzędzia AI. Wymagają za to od nas samodzielnej konfiguracji i zasobów potrzebnych do ich działania.
Lokalne modele to sposób na odzyskanie części kontroli nad przetwarzaniem danych przez narzędzia AI (i kosztami). Dla chętnych to również droga do tańszego rozwijania własnych narzędzi na podstawie modeli AI. Nikt nie obiecuje, że jest to równie łatwa droga, co odpalenie strony z gotowym chatbotem, ale zdecydowanie jest warta eksploracji, a dla wielu organizacji powinna być coraz ważniejsza.

Różne scenariusze wykorzystania lokalnych modeli LLM
Lokalny model to szerokie hasło, pod którym skrywa się kilka podejść i rodzajów modeli AI. Zależnie od tego, czy szukasz alternatywy dla korzystania z ChatGPT, czy Gemini dla siebie lub dla całej organizacji i jaki masz budżet (pieniędzy i czasu), możesz rozważyć jedną z tych opcji:
Model na komputerze użytkownika
Najprostsze rozwiązanie dla indywidualnych użytkowników/czek. Wymaga „tylko i aż” zainstalowania aplikacji, pobrania modelu z sieci oraz odpowiednio mocnego komputera. Dane zostają na urządzeniu – o ile sam nie włączysz funkcji, które wysyłają coś na zewnętrzne serwery (np. zewnętrzne wyszukiwanie, integracje, zdalne logowanie). W tej konfiguracji nie płacimy subskrypcji ani kosztów korzystania z API (zależnych od tego ile korzystamy z modelu), ponieważ praca modeli (tzw. inferencja) odbywa się na naszym komputerze. Potrzebujemy za to do tego mocnego sprzętu, zwłaszcza karty graficznej i pamięci RAM.
Model na serwerze organizacji
Podobne rozwiązanie do samodzielnego hostowania stron WWW lub oprogramowania dostępnego zdalnie (np. serwera plików). Zespół korzysta ze wspólnej instancji (np. z kopiami zapasowymi, współdzielenie czatów z narzędzie AI itp.). Wymaga to jednak przygotowania i administracji serwerem dostosowanym do uruchomienia i działania modelu AI. Podobnie, jak w przypadku indywidualnego komputera, zdecydowanie mocniejszego niż przeciętna maszyna do hostowania plików. W tym modelu również nie płacimy subskrypcji ani nie ponosimy kosztów korzystania z API, ponieważ praca modeli odbywa się na naszym sprzęcie. Ponosimy za to koszty sprzętu i jego działania.
Model AI w centrum danych naszego wyboru
Rozwiązanie kompromisowe, a zapewne najbardziej odpowiednie dla dużych organizacji. Wybrany przez nas model działa w centrum danych, które posiada odpowiednie maszyny, a my mamy do nich dostęp zdalny. Nadal wysyłamy dane po sieci, ale możemy realizować łatwiej dodatkowe wymogi np. bezpieczeństwa przetwarzania danych, umowy powierzenia, standardy zabezpieczeń. To rozwiązanie umożliwia również wybór dostawcy, który działa w Unii Europejskiej. Ponosimy tutaj koszty usługi u wybranego dostawcy.
Dodatkowo warto rozróżnić modele otwarte (open source) od modeli o otwartych wagach (open weight). Oba rodzaje są dostępne za darmo i można uruchamiać je lokalnie. Tylko modele open source dają pełen wgląd w kod i dane. Modele open weight udostępniają tylko parametry treningowe. Ma to znaczenie dla tych bardziej zaawansowanych zastosowań np. organizacji, które chciałby rozwijać własne narzędzia, dopasowywać model w przyszłości lub potrzebują transparentności dot. danych, na których model był trenowany.
Modele, czyli z czego wybierać?
Wiesz już, że model modelowi nierówny. To, który będzie odpowiedni dla Ciebie, zależy od wielu czynników:
- możliwości sprzętowych twojego komputera lub serwerów, na których ma działać;
- parametrów, na których Ci zależy np. szybkości działania, kosztów;
- zadania do wykonania np. lepszej sprawności w języku polskim, efektywności transkrypcji audio, wyspecjalizowaniu w klasyfikacji dokumentów, pisaniu lub kodowaniu. Wiele modeli posiada specjalne wyspecjalizowane wersje do określonych zadań;
- poziomu otwartości modeli i transparentności danych treningowych. Na przykład, jeśli planujesz korzystać z modelu AI do zadań związanych z medycyną, prawdopodobnie potrzebujesz dokładnej wiedzy, o tym, jak w tym zakresie model był trenowany;
- tego, kto tworzy model, np. może zależeć Ci na wykorzystaniu modelu rozwijanego w Europie (np. Francuski Mistral lub polski Bielik).
Nie obawiaj się, kiedy widzisz w bibliotekach modeli AI tysiące nazw brzmiących np. tak: „qwen2.5-14b-instruct-q4_k_m.gguf”. Poza poszukaniem opisu i dokumentacji warto rozpoznawać, co znaczą fragmenty tych nazw.
- Qwen to nazwa rodziny modelu pochodzącego zwykle od jednej firmy (w tym przypadku chińskiej firmy Alibaba).
- 2.5 to wersja modelu.
- 14B mówi o skali modelu (liczbie parametrów). Większe modele zwykle lepiej radzą sobie z bardziej złożonymi zadaniami, ale mogą wymagać większej pamięci, kosztować więcej podczas pracy.
- Instruct / Chat sugeruje, że model był dostrajany do wykonywania poleceń i rozmowy.
Q4/Q8 to poziom kwantyzacji (kompresji). Q4 to popularny poziom kompromisowy, jeśli zaczynasz. - GGUF / MLX / AWQ/ EXL2 to formaty, które wpływają na kompatybilność i wydajność na danym sprzęcie. GGUF działa na dowolnym sprzęcie posiadającym odpowiednią moc procesora i karty graficznej. MLX tylko na procesorach Apple. AWQ/GPTQ/EXL2 tylko na procesorach firmy NVIDIA.
W sieci znajdziesz setki porównań i list (tzw. leaderboards) modeli AI poddawanych zróżnicowanym testom. Na początek zdecydowanie nie warto gonić za tym, kto w danym momencie jest na topie jakiejś listy. Lepiej posłużyć się rekomendacjami od sprawdzonych źródeł np. społeczności Hugging Face.
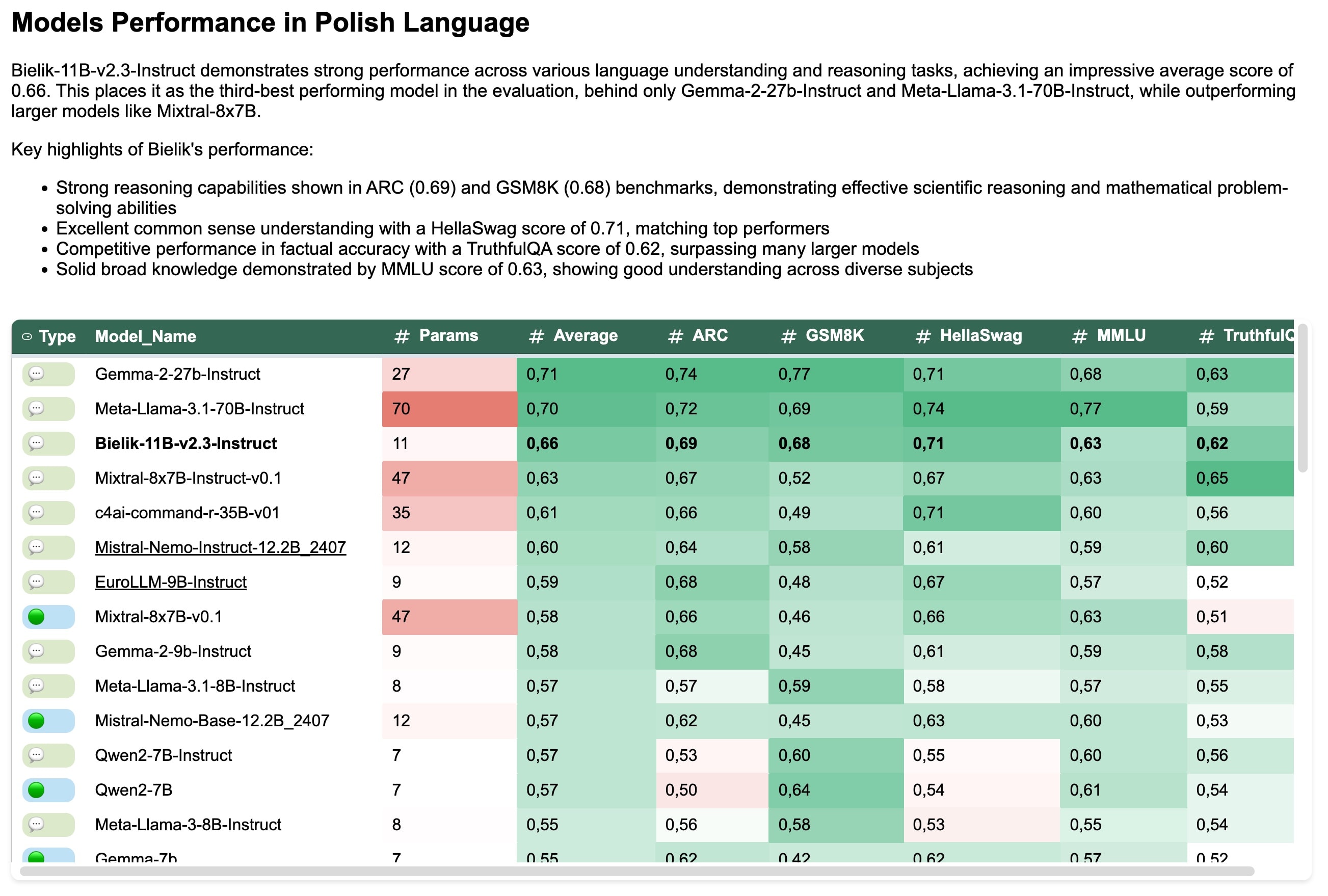
Mateusz Kardaś, który prowadził śniadanie Sektora 3.0 o lokalnych modelach AI, poleca na start spośród modeli topowych (porównywalnych do tego, co oferują np. ChatGPT i Gemini) modele pochodzące z Chin:
- Kimi K2
- DeepSeek R1
- DeepSeek V3.1
A także spośród modeli odrobinę słabszych, zoptymalizowanych do lokalnego działania:
- Llama 70B (tworzone przez firmę Meta, rozwijane przez wiele innych firm globalnie);
- Qwen 7B-72B (chiński wielojęzyczny model, sprawny w języku polskim);
- Mistral Small 24B (francuski model, szybki i efektywny);
- Phi-4 14B (mniejszy lokalny model Microsoftu, wyspecjalizowany do zadań takich jak kodowanie, rozumowanie).
W praktyce decyzja o wyborze modelu jest bardziej skomplikowana od wyboru „najlepszego, na który mnie stać”. Wybierz model, który działa stabilnie na twoim sprzęcie i dobrze obsługuje twoje zadania. Najwięcej informacji o modelach AI znajdziesz na stronie wspomnianej biblioteki HuggingFace.
LM Studio, Llama czy Jan.ai? Od jakich narzędzi zacząć?
Aby uruchomić lokalne modele AI na laptopie bez konieczności programowania, zacznij od prostych narzędzi z graficznym interfejsem, takich jak LM Studio. Te aplikacje pozwalają pobrać i rozmawiać z modelami, takimi jak Llama czy Mistral bezpośrednio na Twoim sprzęcie, bez chmury.

- LM Studio jeden z najprostszych sposobów na start: to aplikacja do uruchamiania lokalnych modeli z wygodnym katalogiem i pobieraniem modeli oraz opcją uruchomienia lokalnego serwera lub przez API do modeli, które takie udostępniają.
- Jan.ai, podobnie do LM Studio, to aplikacja z wbudowanym katalogiem modeli do pobrania i uruchamiania lokalnie.
- AnythingLLM umożliwia pracę AI z dokumentami na naszym dysku, czyli tzw. pracę w modelu RAG (Retrieval Augmented Generation). To podobne (choć nie identyczne rozwiązanie) do Google NotebookLM. Posiada wersję desktopową i wymaga odrobiny konfiguracji.
- Ollama to rozwiązanie bardziej narzędziowe i zaawansowane, np. do automatyzacji i pracy przez terminal i API. Narzędzie posiada świetną dokumentację, ale będzie wymagać od nas odrobiny umiejętności cyfrowych, takich jak obsługa terminalu na naszym komputerze.
Plan, czyli co dalej
Jeśli jesteś osobą przekonaną do wypróbowania lokalnych modeli AI dla Twojej organizacji, oto kilka kroków, od których sugerujemy zacząć.
Spróbuj określić, jaki cel ma mieć zastosowań lokalnego modelu np.:
- obniżenie kosztów korzystania na co dzień z narzędzi AI;
- potrzeba bezpiecznej pracy na danych bez przesyłania ich do chmury;
- potrzeba zbudowania wewnętrznej bazy danych, z którą można konwersować z pomocą narzędzi AI, nad którą będziecie mieć pełną kontrolę;
- potrzeba pracy offline.
Zależnie od celu możesz pomyśleć o przetestowaniu narzędzi i modelu.
Na przykład dla obniżenia kosztów i pracy offline, oszacuj możliwości sprzętowe komputerów w organizacji, wybierz program i model, który będzie działać, a następnie przetestujcie lokalny model AI jako alternatywę do dotychczasowych narzędzi AI.
Do tworzenia wspólnej bazy wiedzy, z którą możecie pracować, zacznijcie od przygotowania małego prototypu. Wybierzcie jeden typ dokumentu, który wykorzystujecie często w organizacji (np. procedury HR, baza wiedzy dot. produktu lub usługi, polityki bezpieczeństwa). Opracujecie na ich bazie bazę wiedzy (np. z pomocą AnythingLLM) i jasno ustalcie, co może tam trafić, a co nie np. z perspektywy bezpieczeństwa danych, aktualności informacji. Przetestujcie rozwiązanie na laptopach, zanim podejmiecie decyzję o budowaniu takiego rozwiązania na większą skalę na serwerach dostępnych zdalnie. Po drodze oceniajcie jakość odpowiedzi, czas pracy modeli, napotykane trudności (np. z interfejsem). To pozwoli Wam lepiej określić Wasze potrzeby, dobrać lepsze narzędzia i modele lub rozmawiać ze specjalistami.
Duże modele językowe lokalnie – słowniczek pojęć
Model LLM (Large Language Model) – duży model językowy, czyli algorytm sztucznej inteligencji wytrenowany na ogromnych zbiorach tekstów, który służy do analizy tekstu i generowania tekstu (m.in. odpowiedzi, streszczeń, klasyfikacji informacji i dialogu); w lokalnym AI jest to sam „silnik” (kod i wagi) uruchamiany na własnym komputerze, serwerze organizacji lub w wybranym centrum danych, a wybór pierwszego modelu zależy od typu rozwiązania, praktycznych zastosowań i tego, jakiego zakresu konkretnych zadań ma dotyczyć.
Inferencja (Inference) – proces działania modelu LLM polegający na przetwarzaniu zapytania i generowaniu odpowiedzi w czasie rzeczywistym; przy lokalnym uruchamianiu inferencja odbywa się na własnym sprzęcie, co może przynieść znaczące oszczędności (brak kosztów API i subskrypcji), ale jednocześnie stawia wymagania sprzętowe i wymaga odpowiednich zasobów sprzętowych, zwłaszcza gdy planujesz pracę na większej skali lub z bardziej wymagającymi zadaniami.
Wagi (Weights) – zapis wiedzy i umiejętności modelu LLM powstały w trakcie treningu, który decyduje o tym, jak model rozumie język i jakie odpowiedzi generuje; w praktyce są to pliki pobierane razem z modelem do lokalnego uruchamiania, a w zależności od licencji mogą być udostępniane jako open source (z pełnym wglądem w kod) lub w innych wariantach, co ma znaczenie przy budowie narzędzi do konkretnych zadań, integracji z różnymi narzędziami i pracy na wrażliwych danych.
Parametry (np. 7B, 14B) – liczba elementów wewnętrznych modelu LLM (zwykle podawana w miliardach), która opisuje skalę i złożoność modelu; mniejsze modele częściej sprawdzają się przy ograniczonych zasobach i w lokalnym uruchamianiu na laptopie, natomiast zaawansowane modele zwykle oferują lepszą jakość w bardziej złożonych scenariuszach (np. rozbudowana analiza danych), ale wymagają wyraźnie większych zasobów sprzętowych, dlatego dobór parametrów powinien wynikać z praktycznych zastosowań i realnych możliwości sprzętu.
RAG (Retrieval Augmented Generation) – sposób wykorzystania modelu LLM, w którym generowanie odpowiedzi jest wspierane przez wyszukiwanie informacji w zewnętrznych dokumentach (np. plikach tekstowych i PDF-ach), aby model odpowiadał na podstawie dostarczonego kontekstu; w lokalnym AI RAG jest szczególnie przydatne do pracy na własnych danych i budowania wewnętrznych baz wiedzy, bo pozwala uzyskiwać odpowiedzi dopasowane do konkretnych zadań bez wysyłania treści do chmury, a także łączyć model z różnymi narzędziami (np. do przeszukiwania dokumentów), niezależnie od tego, czy wybierasz rozwiązania takie jak Mistral AI, czy inne modele uruchamiane lokalnie.
Przeczytaj także:
- Jak dbać o prywatność i chronić dane w dobie generatywnej sztucznej inteligencji? Poradnik
- AI, która doskonali twoją pracę z AI
- Czym jest Perplexity AI? Wyszukiwarka i narzędzie z AI w jednym
- Jak bezpiecznie korzystać z generatywnej sztucznej inteligencji?
- How to safely use generative AI like ChatGPT, Midjourney & DALL-E
- AI lokalnie na twoim komputerze. Jak przetwarzać wrażliwe dane bez wysyłania ich do chmury?